HTML版
この教材は、イリノイ大学が作成した教材を日本語に翻訳するとともに、日本の状況に合わせて改訂したものです。
Sandi Caldrone
Assistant Professor, Research Data Librarian
University of Illinois at Urbana-Champaign
caldron2@illinois.edu
Lauren Phegley
Research Data Engineer
University of Pennsylvania Libraries
lphegley@upenn.edu
2022年11月作成
2025年8月更新
はじめに
この教材について
この教材はイリノイ大学アーバナ・シャンペーン校(UIUC)図書館の研究データサービス部門が大学構成員向けに作成した資料を、九州大学データ駆動イノベーション推進本部 研究データ管理支援部門/九州大学附属図書館 図書館DX支援室が日本語に翻訳するとともに、日本の状況に合わせて改訂したものです。研究データマネジメントのベストプラクティスについてもっと学びたい方であれば、どなたでもご利用いただけます。
イリノイ大学のワークショップやウェビナーで扱っている情報の多くが含まれていますが、いつでもアクセスできるセルフガイド式になっています。網羅的な内容ではなく、特に以下の情報を提供しています。
- 研究データ管理ライフサイクルの広範かつ綿密な全体図
- これらのトピックについて詳しく調べるために利用できる、厳選された信頼性の高いリソースへのリンク
- 検索に活用できる、役に立つ専門用語
データ管理が初めての方は、研究の過程全体を通じて参考にできるリソースとなり、自信を持って基礎固めができることでしょう。
経験豊富な研究者の方は、これまでのデータ管理の習慣を改善するためのヒントが満載の便利な復習ツールとして、このリソースをご活用いただけます。
イリノイ大学が作成したオリジナルの教材は、イリノイ大学研究データサービスのウェブサイトで閲覧できます。オリジナルの教材では、マウス操作で視覚的に学習できるPrezi版も利用可能です。
ライセンスと引用時の表記例
本著作物はCC BY 4.0の下でライセンスされています。
Caldrone, S., & Phegley, L. (2022). Self-Guided Research Data Management Workshop [Text]. University of Illinois at Urbana Champaign. https://researchdataservice.illinois.edu/self-guided-workshop/
著者紹介
Sandi Caldroneはイリノイ大学図書館研究データサービス部門の研究データライブラリアン。
Lauren Phegleyはペンシルバニア大学図書館の研究データエンジニア、元イリノイ大学研究データサービス部門の大学院助手。
参考文献
本書では、可能な限り参照リソースへのリンクを明示しています。また、原文の完全な参考文献リストをZoteroで一般公開しています。
データについての序論
データは食材のようなものです。研究で得られた知見がケーキなら、データはケーキを焼くために使う材料です。
それらは可能性に満ちており、他の研究者は別の使い方によってワッフルやピザ生地を作るかもしれません。
情報を作るためにデータを処理し、その情報を提示して、新しい知識を得るためにそれを消費する他者と共有するのです。

研究データの定義
研究データとは、研究の過程、あるいは研究の結果として収集・生成される情報です。仮説を検証するために使用されたり、結論を導くための根拠となります。また、のちに研究結果が正しいかどうか確認するために使用されることもあります。1
- 九州大学データ駆動イノベーション推進本部研究データ管理支援部門、九州大学附属図書館図書館DX支援室「はじめよう、研究データ管理」第1章、p13 ↩︎
テキスト、数字、画像、動画、音声など、研究の過程で観察・記録され、あなたの分析の基礎となるほぼすべてのものがデータです。
データとして認められる記録
研究記録であればすべてがデータというわけではありません。データは研究から生まれた記録された事実資料ですが、それには一般的に何が含まれるのでしょうか?
データ:
- 観察記録
- 測定値
- 録音・録画や転写物
- 要約統計量、グラフ、または図表の基となる記録
データではないもの:
- 論文のドラフト
- 予備分析
- 今後の研究計画
- 要約統計量、グラフ、図表
研究者らが定義するデータ
様々な分野の学者がどのようにデータを定義しているか、ノースカロライナ大学チャペルヒル校のオーダム研究所による3分間の動画をご覧ください(英語のみ)。
FAIRデータ
FAIR原則とは、データの再利用を最大限可能にするためにデータの整理、記述、共有について設けられたガイドラインのことです。これらの原則は、幅広い学問分野にわたり学界で一般的になりつつあります。
FAIRは、Findable(見つけられること)、Accessible(アクセスできること)、Interoperable(相互運用できること)、Reusable(再利用可能であること)の頭文字をとった略語です。
原則
F – Findable(見つけられること)
データは人や機械による検索で見つけることができる。
- データにはグローバルで一意の識別子がある。
- データがリッチなメタデータで記述されている。
- データのインデックスが作成されており、オンラインで検索可能である。
A – Accessible(アクセスできること)
データファイルは、理想的には専用ソフトウェアを必要とせずに開くことができる。
- 誰がどのようにデータにアクセスできるかが明確である。
- データにアクセスできなくても、データの説明にはアクセスできる。
- データにアクセスするために必要なソフトウェアがすべて無料で公開されている。
I – Interoperable(相互運用できること)
データは他のデータ、アプリケーション、ワークフローに接続可能である。
- データとメタデータが標準的なスキーマと語彙を使用している。
R – Reusable(再利用できること)
データは完全に理解可能であり、新たに再利用することが認められている。
- データを理解するために必要な文脈がリッチなメタデータにより提供されている。
- データが再利用のためにライセンスされている。
- データの出所が明確である。
FAIRy Tale(データのおとぎ話)
話が少し抽象的になり過ぎたでしょうか。その場合、楽しいナレーションでFAIRデータについて説明しているストーリーFAIRy Tale をどうぞご覧ください(英語のみ)。
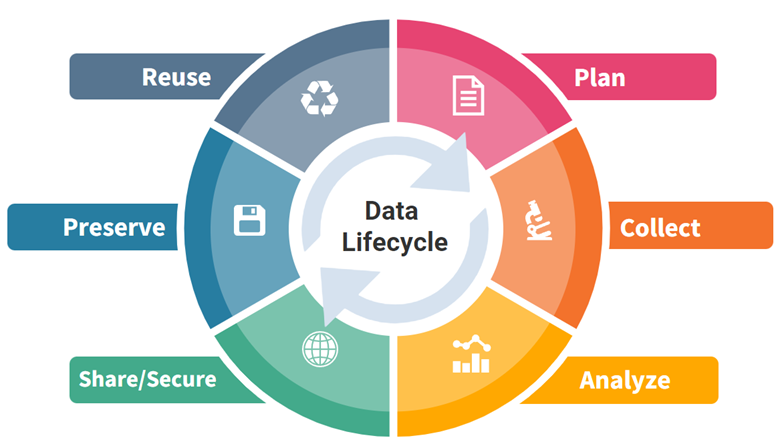
データ管理ライフサイクル
この教材は、6つのステージを含む研究データライフサイクル図を中心に構成されています。この図は、右上から時計回りに次のようになっています。
- 計画 (Plan)
- 収集 (Collect)
- 分析 (Analyze)
- 共有/セキュリティ (Share/Secure)
- 保管 (Preserve)
- 再利用 (Reuse)
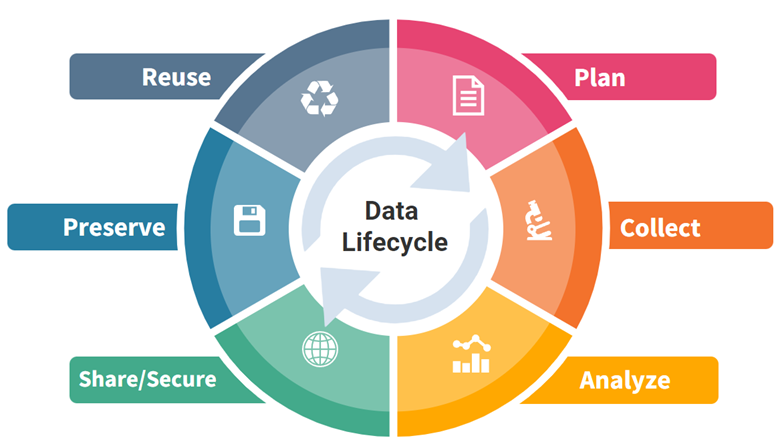
6つのステージはそれぞれ3つの関連するセクションからなり、セクションの長さと深さはトピックによって異なります。
計画
資金提供者を知る
計画を立て始める前に、資金提供者の要件を確認しましょう。ほとんどの資金提供者は、データが可能な限りオープンであること、データのセキュリティが必要なだけ確保されていることを要件として定めています。
データの共有に関する要望や締め切りに関する詳しい指示については、公募要領等を確認しましょう。
SPARCopen.orgで、トップクラスの資金提供機関が求めるデータ共有の要件を確認しましょう。
日本の主要な資金提供機関は以下のとおりです。
・日本学術振興会 科学研究費助成事業(科研費)
・厚生労働科学研究費(厚労科研)
・日本医療研究開発機構(AMED)
・科学技術振興機構(JST)
データマネジメントプランを書く
主要な研究助成金申請書では、データマネジメントプラン(DMP)の作成を義務付けています。DMPは、場合によりデータマネジメントシェアリングプラン(DMSP)とも呼ばれます。DMPを作成する必要がなくても、プロジェクトを始める段階でDMPを作成しておくことは、後々に予想外の事柄や大惨事が起こるのを防ぐのに大いに役立ちます。
共同研究者とともに研究に取り組む場合は、以下のようなことについて、関係者全員が同じ認識でいることを確実にしておくことが特に役立ちます。
- 名称とラベル
- 測定単位
- 保管場所
- セキュリティに関する必要事項
- ファイル共有
DMPに含めるべき事項
U.S National Science Foundation(NSF)の要件に基づく事項は以下のとおりですが、一般的にも適用可能です。
- データ型
- タイプ
- 形式
- 量
- メタデータ
- ラベル
- 構成
- 一貫性
- アクセス
- 共同研究者
- セキュリティ
- 機密性
- 再利用
- 共有
- 出版
- ライセンシング
- アーカイブ化
- バックアップ
- ファイル形式
- リポジトリ
データ管理計画ワークブック
このワークブック(オリジナル英語版。編集可能なWordファイルとして入手可能)ではデータ管理を簡単な質問へと分解しており、DMPを最初から最後まで作成するのに役立ちます。
これらの質問に答えると、資金提供者が要求するDMPおよびDMSPの様式に回答を入力できます(ただし、海外の資金提供者が求めるDMPに準じたものです)。

DMPの遂行
データプランを遂行するための重要なポイント(特に共同研究の場合)
- 全員がDMPのコピーを有していること - オリエンテーションに組み込みましょう
- 全員から署名済みのコピーを集めて保管すること - メンバーがDMP に対して真摯になるのに役立ちます
- 特定の研究メンバーに役割を割り当てる - バックアップ、ファイル整理など
- 状況の変化に応じて見直すこと -DMPは生きた文書であるべきです
- 共有ドライブに保管すること - 探しやすくしておきましょう
収集
メタデータ
データに関するデータとも呼ばれることもあるメタデータは、データを解釈するために必要なコンテキスト情報を記録しているものです。
メタデータはラベルという形を取ることが多いですが(例えばファイル名や列のヘッダー)、文書の場合もあります(例えばReadMeファイル)。文書の場合については、共有/セキュリティの章で説明します。
ファイル名
ファイルを整理するために最も重要なことは、ファイルの命名規則を設定することです。
ファイル名は、次の特徴を持っているべきです。
- 明確であること
- 一貫していること
- 一意であること
ファイル命名規則を書く
- プロジェクトに関連する属性情報をいくつか特定してください。
- 範囲の最も広い属性情報から最も狭いものへと並び替えてください。
- 各属性情報に何が入るか定義してください。
- 例も示してください。
まずは、このファイル命名規則のテンプレートを使ってみてください(オリジナル英語版)。
実際の例
本節では、イリノイ大学アーバナ・シャンペーン校の研究室で作成された実際のファイル命名規則を扱います。この規則ではファイル名の4つの要素を識別しており、最も広いカテゴリ(プロジェクト名)から最も狭いカテゴリ(日付)へと進みます。斜字テキストは、例からそのまま引用したものです。
ファイル名要素#1 - プロジェクト名
全ての実験データ、統計、グラフファイルは以下のとおり命名すること
- プロジェクト名
- BSUB6755
- UICCC
- TRT
- LAS56
ファイル名要素#2 - 実験グループ
- 実験グループ
- 実験グループと番号のマスターリストを参照すること(例:GP129)
ファイル名要素#3 - ファイルの種類
- ファイルの種類
- Data(生データ)
- Statsi(Rへのインプット)
- Statso(モデルのアウトプット)
- Graphi(Rのggplotへのインプット)
- Grapho(ggplotで作成したグラフ)
ファイル名要素#4 - 日付
- 日付
- 国際標準YYYY-MM-DDを使用すること(例:2012-09-23)
この規則を用いたファイル名の例
ファイル名の例:「UICCC_GP129_grapho_2012-09-23.jpg」は、2012年9月23日にUICCCプロジェクトの129グループによるデータから作成したグラフ形式のアウトプットです。
より良いファイル名を付けるためのヒント
最も優れたファイル名は、以下の要素が含まれています。
- 短く一貫性のある記述子
- 小文字と数字
- スペースではなくハイフンまたはアンダースコア
- YYYY-MM-DD形式の日付
- バージョン番号(例:v01)
- ファイル形式を示す標準的な拡張子
ファイル命名に関する参考資料
まだご納得いただけませんか?この数分間の動画では、データ・ライブラリアンのKristen Brineyが、命名規則がいかにあなたの研究生活を楽にしてくれるかについて説明しています(英語のみ)。
スキーマ
メタデータのスキーマは、データを記述するための構造や構文を提供します。
共有された構造のおかげで、メタデータは機械可読化されるようになり、データは容易にインデックスされ、見つけられやすくなり、オンライン上で提供されます。
スキーマは必要か?
リポジトリにデータを登録すると、作成者、タイトル、公開日などの標準的な記述子を含む、データセット全体に対する一般的なメタデータスキーマが適用されます。
ほとんどのスキーマを記述した文書は非常に専門的で、情報の専門家向けに書かれています。
どのスキーマがあなたのデータに最も適しているかは、データを登録する予定のリポジトリに問い合わせてください。
統制語彙
統制語彙は、ある分野またはグループで一貫性を保つために用いられる記述的な用語の標準的なセットのことです。
例えば、米国国立農業図書館類語辞典では、作物の名称の標準セットを提供しています。
メタデータを充実させるような統制語彙があなたの研究領域についてあるかどうか知りたい場合は、図書館に尋ねてみましょう。
スキーマに関する参考資料
スキーマについてさらに学びたい方は、広く用いられている以下のスキーマをご覧ください(英語のみ)。
- Dublin Core - 一般スキーマ
- DataCite - データセット用
- Data Documentation Initiative(DDI) - アンケート調査や社会科学データ用
データの整理
場当たり的に都合の良いやり方でデータを整理し続けると収拾がつかなくなって、後が大変です。
データ収集は計画を立てるところから始め、長い目で見て時間も労力も節約できるようにしましょう。
「きれいな」表を作るためのヒント
表形式のデータは、以下のヒントに従ってきれいにしましょう。
- 1列に1種類のデータ
- 1行に1つの観察事項
- 1つのセルに1つの値
- NULL値を記録する方法は1種類
- リッカート尺度は1方向
データに関して言えば、「きれいな」とはただ整理整頓ができていることを意味することもあれば、データの達人Hadley Wickhamが開発した具体的なフレームワークのことを指すこともあります。詳しくは、きれいなデータに関するこの画期的な論文を参照してください。
フォルダとディレクトリ
ディレクトリ、またはフォルダ構成の目的は、プロジェクトにとって正しいアプローチを見出すことに尽きますが、これについて以下の一般的なガイドラインが役に立つでしょう。
- すべてのファイルを一ヵ所に保管してバックアップを取りましょう。
- フォルダのすべてにサブフォルダを作成することはしないようにしましょう。
- 時系列にソートできるよう、日付はYYYY-MM-DD形式にしましょう。
- デジタルでも実物でも、記録を管理するために同じ構成に従って整理しましょう。
- 本ガイドのメタデータの節で説明しているファイル名に関する提案に従ってください。
ファイル名とディレクトリの場所から、ファイルに何が入っているのかが分かることが必要です。
整理の基準:
- 授業科目
- プロジェクト
- 研究室
- 標本
- 研究者
- データセット
- データ型
- その他何でも、あなたに都合の良いもの
バックアップとバージョン
バックアップは今すぐ始めましょう!アーカイビングはプロジェクトの終了時まで待ってから始めることもできますが、バックアップはデータを収集し始めると同時に始める必要があります。
ワンポイントアドバイス:研究を遡らなくてはならなくなった場合に備えて、データのクリーニングを始める前に必ずデータを保存してコピーをロックし、さらに分析を始める前にももう一部コピーをロックしておきましょう。
3-2-1 バックアップ
この簡単な戦略は、あらゆる研究プロジェクトに該当します。元のファイルとバックアップを同じ場所に保存しないこと。ストレージ提供元がバックアップに関するあなたのニーズにすべて対応してくれると思い込まないようにしてください。
少なくとも以下の事柄についてはあなたが責任を持って行う必要があります。
- 重要なファイルのコピー3部を用意し、
- 2つの異なる記憶媒体に保存し、
- さらに1部を遠隔地に保存
使用するストレージがすべてクラウド上にある場合、コピーを1部オフラインで保存することも検討してください。
バージョン管理
重要な変更を記すために、バージョン管理によって各ステップを辿れるようにしてください。
桁揃えのためのゼロ(0)を使ってファイル名にバージョン番号を入れ(例えばfilename_v02.csv)、バージョン表に変更点を記入してください。
Google Docsなど、一部の編集ツールでは自動的にバージョンを追跡してくれますが、次の二つの理由からあなた自身によるバージョン管理が役立ちます。
・ツールは大きく重要な変更と軽微で意味のない編集を区別できません。
・ツールは数多くのバージョンを保存できるものの、どのツールにも限界があります。必要なだけ遡れないことがあるかもしれません。
バージョン番号、著者、変更点、日付の列を含む簡単な表でバージョンを追跡できます。
| バージョン番号 | 著者 | 変更点 | 日付 |
| 01 | HL | リリースしたバージョン | 2022-01-10 |
| 02 | SC | セクション2を修正 | 2022-01-15 |
分析
ヒント&トレーニング
他のあらゆることと同じように、データスキルも定期的に使わなければ衰えてしまいます。
以下のヒントやリソースに目を通し、新しいスキルを学び、最新の技術についても知っておきましょう。
表に関するヒント
優れたデータ表のカギ - 相互運用性への考慮
- 短く簡単な項目名を使ってください - 1行のみにすること
- 重要なバージョンのコピーはロックしてください - 生データ、クリーンデータ、分析済みのデータなど
- 欠損データについては空白セルのみを使用してください - NULL値については「NULL」「NA」「0」「-」などを使うこと
- メモを残してください - 何をなぜ行ったのか記録すること
- 1ファイルあたり1つの表を保存してください(機械可読性を確保するため)
- 可能であればCSV形式で保存してください(保存や共有のため)
ツール
表、テキスト、または画像を使用していますか?コーディングを試してみる準備はできていますか?以下のオープンソースのソフトウェアはデータクリーニングや分析を簡単、安全かつ効率的に行えるようにしてくれます。 これらのツールは「言論の自由」の「自由」と同じ意味で「free」であって、オープンソースであるため、使用に制限はありません。また、これらは「無料ピザ」の「無料」と同じ意味でも「free」であって、無償で利用できます。
OpenRefine(英語のみ)
ExcelのようでExcelよりも優れているOpenRefineはGoogle Refineとも呼ばれ、パワフルなデータクリーニングの機能がある使いやすいスプレッドシートツールです。
エクセルを使い慣れているものの雑なデータをもっと素早くクリーンアップできたらと思っている方には、まさにOpenRefineが解決策かもしれません。
- Software (英語のみ)
- User Manual (英語のみ)
- Beginner’s guide (英語のみ)
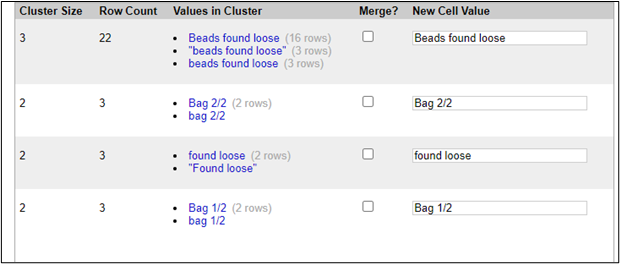
考古学の例
この考古学データセットの例では、OpenRefineがほぼ同一の値を自動的に識別し、それらを簡単に統合する機能を用意してくれているのが分かります。
Voyant (英語のみ)
テキストデータの探索では、ウェブベースのテキスト読み取り・分析環境であるVoyant Toolsが特に自然言語処理やデジタル人文科学研究に役立ちます。
まず初めに、ただテキストをウェブサイトに貼り付けてください。Voyantが自動で複数の分析を行い、探索したりカスタマイズできる様々な図表を載せたダッシュボードを表示してくれます。
- Voyant Tools (英語のみ)
- Getting Started Guide (英語のみ)
ジェーン・オースティンの例
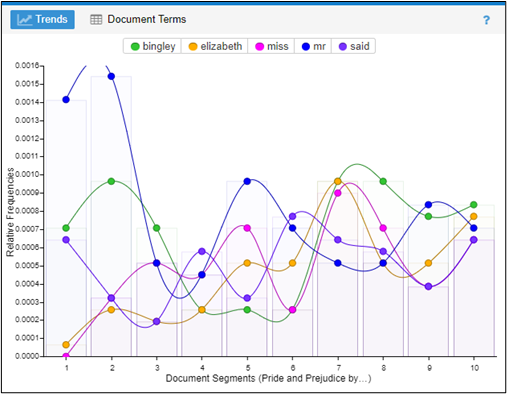
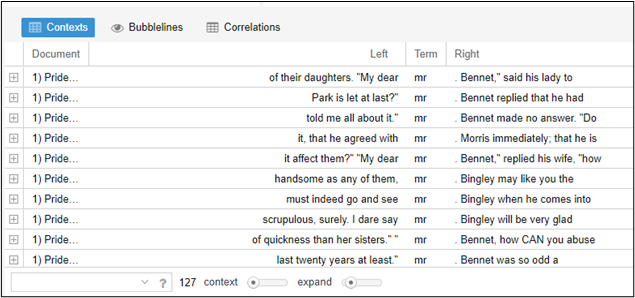
以下の画像は、VoyantがJane AustenのPride and Prejudiceの最初の10章を使ってできることの例です。これらは、最も頻繁に使われている単語のワードクラウド、最も頻繁に出現する単語が各章で現れる頻度を表した線グラフ、頻繁に出現する単語の直前と直後のテキストを示した共起表です。
Tropy (英語のみ)
Tropyは、研究用の写真を整理するのに役立ちます。次のことができます。
- 画像を組み合わせる
- リストを作成
- タグや注釈を追加
- 一括編集
- 文字起こし
- などなど…
Tropyは研究用保存資料の写真を対象としていますが、どのような写真整理プロジェクトにも使えます。
- Tropy Software (英語のみ)
- Getting Started Guide (英語のみ)
古代ギリシャ語の例
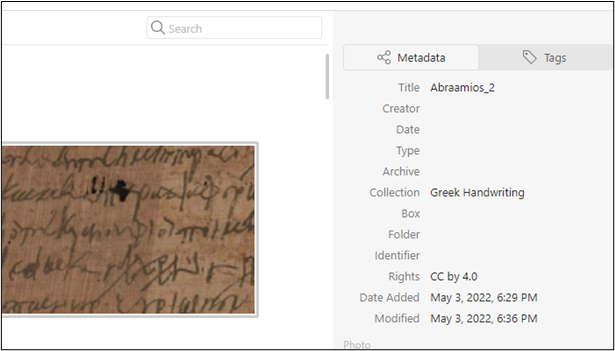
Tropyコレクションに含まれるこの画像の拡大画像は、古代ギリシャ語の手書きのアーカイブコレクションに含まれる画像のメタデータの追加や編集が如何に直感的であるかを示しています。
RとPython
プログラミングまたはコーディングにより、研究者は研究データの分析を効率化し、再現性のある研究を実践し、データやレポートを他の研究者たちと簡単に共有することができます。
プログラミングには最初圧倒されるかもしれませんが、コードで試行錯誤してみることをお勧めします。言語を学ぶようなもので、触れれば触れるほど分かるようになります。
RやPythonといったツールは比較的馴染みやすく、コンピュータサイエンスのバックグラウンドを持たない研究者の間で広く使われています。また、これらは広くサポートされているので、説明やサンプルコードもオンラインで簡単に見つかります。
RとRStudio
Rは統計的な計算やグラフィックスのために開発されたプログラミング言語です。表形式のデータを扱う多くの分野で一般的に使われています。
RStudioは、Rコードを書く上で広く使われているツールです。ほとんどのユーザには、無償のオープンソース版がよいでしょう。
Rを使い始める
RやRStudioを学ぶのに役立つ、無償の充実したリソースはたくさんあります。
- R for Reproducible Scientific Analysis - Software Carpentry社によるセルフガイド式の一日ワークショップ
- Garrett Grolemund著 Hands-On Programming with R
- Hadley Wickham and Garrett Grolemund著 R for Data Science
Rについてまったく知らない場合は、一緒に学ぶ人を少なくとも1名探してみてください。コーディングは、誰かと一緒に相談しながらであればずっと簡単になります。
Rに関する便利な参考資料
Rでコードを書くのであれば、使っているパッケージがこれらの便利なcheetsheets(英語のみ)に含まれていないか確認してみましょう。
Rパッケージについて調べているのであれば、その多くが小規模データを扱う上で人気のツールセットであるTidyverseの一部であることに気づくかもしれません。Hadley Wickham氏の記事「Tidy Data」を一読してTidyverseについてもっと学び、適しているかどうか確認してください。
上級Rユーザ
既にRに慣れており、Rに関するスキルセットをさらに充実させたい方は、GitでRのコードのバージョン管理や共有を試してみましょう。Happy Git with Rは、Gitの仕組みとRStudioとの接続方法について丁寧に解説している包括的なガイドです。
自身の研究や教育にRを取り込む準備ができている方は、R Markdownフォーマットを確認してください。実験ノートとして機能し、コードの結果を人間可読な文書やダッシュボードへエクスポートします。
Python
Pythonはデータ解析に広く用いられているパワフルなプログラミング言語で、比較的学びやすいプログラミング言語の一つです。
AnacondaはPythonコードを書くためのソフトウェア環境です。Anacondaには数々のバージョンがあります。「ディストリビューション版」(元「個人版」)はオープンソースで、ほとんどの研究者のニーズに合います。
Pythonを使い始める
Pythonでコードを書いたことがない方は、次のいずれかから始めてみてください。
Charles Severence博士のPython4Everyone講座 (英語のみ)- この無償のオンライン講座は、コードをまったく書いたことがない方にとっても親しみやすい入門です。講座で使われるすべての教材(ebook、講義動画、課題)はPY4Eのホームページで無料で提供されています。全講座を通して学習することも、トピックごとにレッスンを選んで学習することもできます。
Software CarpentriesのProgramming with Python (英語のみ)- このセルフガイド式のワークショップは、Pythonを立ち上げてPythonコードを書き始めるためのステップバイステップのガイドを提供しています。ワークショップは全部で丸1日ほどかかりますが、Pythonの信頼できる入門書です。
他にも自分で使える無数のオンラインリソースがありますが、あなたと一緒に学びたいというグループまたはパートナーを見つけるとより簡単です。
Pythonに関する便利な参考資料
Christian Mayer著「Python One-Liners」(英語のみ)は、かなり便利な短いコードステートメントを「一言コード(one liner)」 として教えるという発想に基づいています。Pythonチートシートや動画のチュートリアルは素晴らしい参考資料です。
最も一般的なPythonライブラリの一つであるPandasは、データを構造化し、分析し、やりとりする方法を提供してくれます。詳しくは、Pandasに関する文書を確認してください。
上級Pythonユーザ
研究の質をさらに高めるために別の方法を模索している上級Pythonユーザの方は、次の二つのオプションを検討してみてください。
Jupyter Notebooksでは、コード、データ、図表などすべてに対して同時に一ヵ所で反復的に作業できます。40種類を超えるプログラミング言語が使えますが、Pythonはアプリケーションで最も使われている言語のひとつです。
新しいスキルやプロジェクトを模索している方は、freeCodeCampのPython Tutorial(英語のみ)を検討してください。ウェブスクレイピングやAPI開発といったトピックのPythonチュートリアルが用意されています。
RとPythonの選び方
RとPythonは同様の能力を備えており、どちらについてもたくさんのリソースやガイド、チュートリアルなどがあります。
両方とも多くの時間をかけて学ぶ必要があるので、同時に学ぼうとすることはお勧めしません。
あなたの研究チームに、既にRかPythonを使った経験がある方はいませんか?いるのであれば、使った経験がある方でいきましょう!
あなたの研究分野ではどちらがより一般的に使われていますか?その場合、最初から始めるのではなく、借用できるコードスニペット(挿入できるコードの断片)を見つけられるかもしれません。
コーディングは情緒的な旅ですので、自分自身に対して忍耐強くなりましょう。きっとうまくいくことでしょう!
データの可視化
ビジュアライゼーション(可視化)は研究結果を伝えるのを助けるだけでなく、探索的データ解析(EDA;名前通りの解析方法)の重要な一部分でもあります。
データ・ビジュアライゼーションにより、次のことが探索しやすくなります。
- 外れ値
- パターン
- 傾向
- グループ化
- さらに調査すべき関心領域
探索することで、クリーンアップする必要がある問題が明らかになることがあります。OpenRefineはこれに適したツールです。
ビジュアライゼーションの基本
データ・ビジュアライゼーションのツールを使うことはデータを探索する良い方法であり、データセットにどのような変数があるのかを把握することから始めるとよいでしょう。それにより、どのようなビジュアライゼーションが自身のデータに最も効果的かを知ることができます。
最終的に、ビジュアライゼーションはコミュニケーションのためのものなのです。どのようなビジュアライゼーションを選択するにしても、ベストプラクティスをいくつか適用してみてください。
変数の可視化
変数には基本的に2つの種類があります。
- 離散変数 ―(例えば、動物種のリストのように明確なカテゴリに分かれている変数)
離散変数には、棒グラフやバブルチャートがよく合います。 - 連続変数 ―(例えば、温度測定値群のように、一連のわずかな変化が広がっている変数)
連続変数を表すには、散布図、線グラフ、ヒストグラムなどが適しています。
変数の種類によって、使用できるビジュアライゼーションの種類が異なります。
ビジュアライゼーションの種類
データ・ビジュアライゼーションといえば、何が思い浮かびますか?棒グラフ?線グラフ?これらの古い表現方法が定番であるのには理由がありますが(簡潔であって読みやすい)、その他にも使える図表はたくさん出回っています!
- 動きや流れを可視化するサンキー・ダイアグラムはどうでしょうか?
- 円グラフを使うことは考えていますか?代わりに比例面グラフを検討してみてもよいかもしれません。
- 無数のカテゴリやサブカテゴリを整理するのに苦労していませんか?あなたが必要としているのは、まさにツリーマップかもしれません。
The Data Visualization Catalogue(英語のみ)では、これらやその他数十種類ものビジュアライゼーションの閲覧可能なディレクトリをご覧いただけます。
図表を選ぶ
データを可視化するのに適したタイプを見つけやすくするために、データ・ビジュアライゼーション専門家のAndy Kirkは図表を5 basic families(英語のみ)にまとめています。
- カテゴリ型 - カテゴリを比較するため(例:棒グラフ、バブルチャート、ワードクラウド)
- 階層型 - 全体を構成する部分を示すため(例:円グラフ、積上げ棒グラフ、ツリーマップ)
- 関係型 - 関係性を探索するため(例:マトリックス図、サンキー・ダイアグラム)
- 時間型 - 経時変化を示すため(例:線グラフ、面グラフ、ガントチャート)
- 空間型 - パターンをマッピングするため(例:ヒートマップ、ドットマップ)
インタラクティブ・チャートピッカー
データを表現するのにどのビジュアライゼーションが最も有効か、From Data to Viz(英語のみ)のチャートピッカーであなたの変数タイプを選択してください。
ベストプラクティス
Stephanie EvergreenのThe Data Visualization Checklist(英語のみ)で紹介されている視覚的コミュニケーションのベストプラクティスは次のとおりです。
- テキストはまばらで力強く - ただ記述するのではなく、メッセージを伝える
- データに明確なラベルを付与すること - 可能であれば、説明文ではなくラベルを使う
- データを意味のあるように並べること - 例えば、最も大きいものから小さいものに
- 正確な比率を使うこと - 形状や大きさを歪めない
- キーポイントを色で強調すること - 対比に使う色の数は多くしない
- シンプルに留めること - 不必要な線は消す
視覚的な例
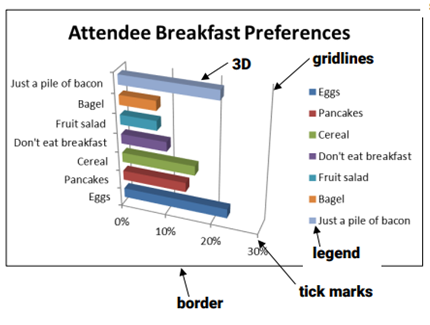
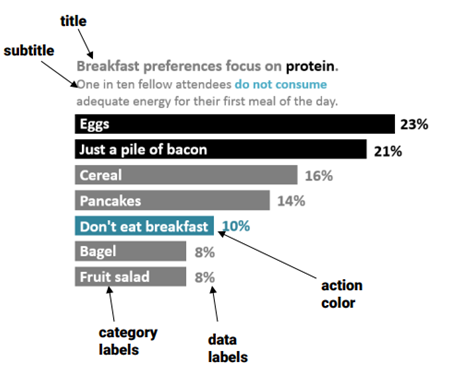
以下の二つの図表もThe Data Visualization Checklistから引用したものですが、いずれも同じデータを可視化しており、前者は悪いデザインの図表、後者はよいデザインの図表になっています。
悪いデザインの図表では変数が特に意味のない順序になっており、多くの色が使われており、ラベルと凡例が同じ情報を繰り返し表しており、グリッド線や3D図形などのデザイン要素が邪魔をしています。
よいデザインの図表では変数を大きい順に並べており、重要な部分に目が行くような二つのボールドカラーや、明確なラベル、そしてデータの概要を表すタイトルとサブタイトルを使用しています。
ビジュアライゼーションが答えるべき5つの問い
Anna Feigenbaum and Aria Alamalhodaei著「The Data Storytelling Workbook」より:
- このビジュアライゼーションは誰、または何に関するものか?
- テーマについて、このビジュアライゼーションは読み手に何を教えているのか?
- この情報はどこで重要なのか?どのような文脈または地理的位置で重要なのか?
- 情報はいつを指しているのか?時間的な位置付け、必要であれば文脈を提供すること。
- 読み手はなぜ関心を持つべきなのか?なぜ重要なのか、あるいは読み手はこの情報で何をすべきか?
「図表のゴミ」を避けるために
名著「The Visual Display of Quantitative Information」において、Edward Tufteは不必要な装飾のことを、三つのカテゴリに分類される「図表のゴミ(chartjunk)」として記述しています。以下のことを避けるようにしてください。
- 意図的ではない視覚効果 - 目を逸らせたりストレスをかけるパターンや視覚的ノイズ。
- 忌まわしいグリッド - データを圧倒してしまうような目立つ太線のグリッド。
- 自己アピールする装飾- デザイン全体を支配してしまう不必要なスタイルや装飾
ビジュアライゼーションに関する参考文献
ビジュアライゼーションについて詳しく知りたい方は、以下を見てください。データ・ビジュアライゼーションについては、数多くのすぐれた本が世に出ています。特に以下の書籍をお勧めします。
データを使ってより良いコミュニケーションを図るための理論・提案・活動について:
Feigenbaum, Anna, and Aria Alamalhodaei.(2020). The Data Storytelling Workbook. Abingdon, Oxon ; New York, NY: Routledge.
スプレッドシートのデータを可視化するための実用的なアドバイス:
Evergreen, Stephanie D. H.(2017). Effective Data Visualization: The Right Chart for the Right Data. Los Angeles: SAGE.
今でも強い影響力を持つ名著:
Tufte, Edward R.(1983). The Visual Display of Quantitative Information. Cheshire, Conn: Graphics Press.
可視化ツール
データを可視化するためのツールは何十種類もあります。ここで取り上げるTableau、R、Pythonの3つは、汎用性が高く、幅広く利用されている確立されたツールであり、それらを使いこなすために役立つリソースもオンライン上にたくさんあります。
RとPythonはどちらも習得するのに時間がかかるプログラミング言語ですが、あなたの研究上でデータ分析が必要であれば、投資する価値があるものです。また、どちらも無償かつオープンソースであり、今後もそうあり続けることが期待されています。これらを学習するための教材については、このガイドの「分析 > ツール」の節も参照してください。
Tableauは馴染みやすく、スタイリッシュなビジュアライゼーションやダッシュボードを構築するための多数のドラッグ&ドロップ機能を搭載したグラフィカル・ユーザ・インターフェイス(GUI)を備えています。様々なバージョンがあり、そのほとんどは有償ですが、Tableau Publicは無償で利用できるオンライン版です。また、学生はデスクトップ版の無償ライセンスに申し込むこともできます。
他にどのようなツールがあるか見るには、Visualizing Data(英語のみ)のリソースギャラリーをご覧ください。
Tableau
気づいていなくても、Tableauのビジュアライゼーションを見たことはきっとあることでしょう。きれいで人目を引くインフォグラフィックスを作成できるため、ニュース系の出版物に人気がありますが、きれいな結果に惑わされてはいけません。その下には強力なデータ分析機能が隠れているのです。
Tableauを使うのに統計学を理解したり、コードを書いたりする必要はありません。ドラッグ&ドロップのインターフェイスは比較的直感的に扱えますが、その使い方を学ぶのに少なくとも数時間はかかると思ってください。
Tableauのウェブサイトには充実したResources(英語のみ)セクションがあり、ガイド、動画、説明書などが用意されています。
また、プリンストン大学のVizEエスノグラフィックデータ可視化研究室による写真を用いたstep-by-step tutorial(英語のみ)では、UFOに関するデータを使ってダッシュボードを作成するための手順を一つ一つ解説してくれます。
Rでデータを可視化する方法
統計分析を行うためにRを使ったことはあるかもしれませんが、Rがデータ・ビジュアライゼーションを作成するために使える堅牢で柔軟なツールでもあることはご存知でしたか?
Base Rでは、散布図、線グラフ、ヒストグラムなどの一般的に使われている図やグラフの多くを作成しカスタマイズできます。
ggplot2 packageはさらに多くのビジュアライゼーションのオプションを提供しており、コードに最低限の変更を施すだけで異なる種類の図表へと簡単に変換できる「グラフィクスの文法(grammar of graphics: gg)」を使っています。
Rについてもっと知りたい方は、本ガイドの「ツール」の節もご覧ください。
参考資料(英語のみ):
- Base Rとggplot2における図表の種類とサンプルコードのギャラリー
- ggplot2のドキュメンテーションとチートシート
- Rによるビジュアライゼーションのセルフガイド式Data Carpentry workshop
- Hadley Wickham著R for Data Scienceのデータ・ビジュアライゼーションの章
- Winston Chang著The R Graphics Cookbook
Pythonでデータを可視化する方法
データを可視化するために選べるPythonライブラリには、最も基本的なものからより複雑なものの順に、次のようなライブラリがあります。
pandasは主にデータの構造化に使われていますが、基本的な図表も作成できます。
MatplotlibはPythonのデータ可視化ライブラリで、最も基本的な棒グラフから注釈付きの極座標グラフまで作成できます。このライブラリは、利用者の必要に応じて複雑にも単純にもなります。
SeabornはMatplotlibを基にしたライブラリで、出版物にふさわしい美しい可視化データを作るのに役立ちます。
Pythonに興味がある方は、本ガイドの「ツール」の節を確認するのもお忘れなく。
参考資料(英語のみ):
- Pythonによるビジュアライゼーションに関するセルフガイド式のData Carpentry workshop
- Jake VanderPlas著Python Data Science Handbook
- Daniel Nelson著Data Visualization in Python
お手軽なオプション
新しいツールの使い方を学習する時間または忍耐力がなければ、すぐに結果が得られる以下の貼り付けるだけで済むオプションを試してみてください(英語のみ)。
- BatchGeo - テキストをペーストし、住所データの表を瞬時に地図に変換
- WordCloud Generator - テキストをペーストし、ワード数カウントと関連性ランキング機能を持つワードクラウドとcsvファイルを取得
データ可視化のインスピレーション
インスピレーションが湧くのを待っていてはいけません。ゴージャスで革新的なビジュアライゼーションのギャラリーを眺めてみたり、情報デザイナーのGiorgia Lupiによる、データ可視化を使って人間のリアルなストーリーを語る方法についての短いTEDトークを観たり、W.E.B. Du Boisの象徴的な手描きのビジュアライゼーションでタイムスリップしてみてください。
参考資料(英語のみ):
- Information is Beautiful - 見事にデザインされたデータグラフィックスの刺激的なギャラリー
- Tableau Viz of the Day - Tableauで作成された様々なインフォグラフィックス
- Anthropographics - 人に関するクリエイティブなデータ・ビジュアライゼーション
- データ・ヒューマニズムに関するTEDトーク - データデザイナーのGiorgi Lupi氏による講演
W.E.B. Du Boisの歴史的インフォグラフィックス
社会学者・活動家・学者のW.E.B. Du Boisは、1900年パリ万博のためにアフリカ系アメリカ人の生活に関する展示を監督し、その中には手書きによるすばらしいデータ・ビジュアライゼーションも含まれていました。
こちらの記事でDu Boisによるビジュアライゼーションをもっと見てみるか、the Du Boisian Visualization Toolkitを使ってあなた独自のビジュアライゼーションをDu Bois流に作成してみましょう。
共有/セキュリティ
データの共有
多くの資金提供者や出版社はデータの共有を義務付けていますが、データを共有すべき理由は他にも数多くあります。
- 研究分野における学問の進歩を加速化させるため
- 研究がより注目されるようにするため
- 引用率を高めるため
- 研究の質の高さを示すため
- 研究者としての評価を確立するため
- データを収集または管理した学生に著者としてのクレジットを与えるため
- 想像力豊かな再利用の機会を創出するため
クイックスタートガイド
このQuick Start Guide(英語のみ)はDryadデータリポジトリによるものですが、どこでデータを共有しようとも便利に参照できます。
Data Availability Statements(データ利用可能性声明)
Data Availability Statements(アクセス声明またはアクセシビリティ声明とも呼ばれる)は、ある出版物の中で参照されているデータセットが他者によってアクセスできるかどうか、またアクセスできる場合はどのようにアクセスできるのかを短く簡潔に説明したもので、例えば次のような文言になります。
The dataset supporting these findings is openly available in the Illinois Data Bank at [URL], under [DOI or other identifier].
これらの研究結果を裏付けるデータセットはIllinois Data Bank [URL] より [DOIまたはその他の識別子] の下で一般公開され、利用可能である。
ステートメントのサンプル
オープンアクセス・リポジトリの場合:
The dataset supporting these findings is openly available in [repository name] at [DOI/URL/reference number].
これらの研究結果を裏付けるデータセットは [リポジトリ名] より [DOI/URL/参照番号] の下で一般公開されている。
出版物に伴う場合:
The dataset supporting these findings is available in the supplemental materials of this article.
これらの研究結果を裏付けるデータセットは、本論文の補足資料より入手可能である。
要請に応じる場合:
The dataset supporting these findings is freely available upon reasonable request to the corresponding author, [name], at [contact information].
これらの研究結果を裏付けるデータセットは、対応著者である [氏名] 宛に [連絡先] まで合理的に要請することで自由に入手できる。
利用制限付のリポジトリの場合:
The dataset supporting these findings is available in [repository name] at [DOI/URL/reference number]. Restrictions apply due to [explanation].
これらの研究結果を裏付けるデータセットは [リポジトリ名] より [DOI/URL/参照番号] の下で入手可能である。[説明] により、制限が適用される。
利用できない場合:
The dataset supporting these findings is not available due to [explanation].
これらの研究結果を裏付けるデータセットは [説明] により入手可能ではない。
Data Availability Statementsのさらなる例
主要な出版社によるData Availability Statementsのサンプルをご覧ください。
ライセンスとエンバーゴ(公開制限期間)
他の多くの学術出版物とは異なり、データは一般的に著作権で保護されませんが、再利用のための条件を含んだライセンスで共有することは可能であり、またそうすべきです。
データをライセンス付きで共有すべき理由は主に3つあります。
- コントロール:必要に応じて、データを再利用できる方法に関する条件を設定するため
- 明確化:データをどのように再利用すればよいのかがわかるように、不確実性を取り除くため
- クレジット:あなたのデータから派生した新しい著作物において、あなたがクレジットされるべきかどうか、またどのようにクレジットされるべきかを明記するため
考慮すべき要因
ライセンスの選択肢を検討し始める前に、次の関係者と確認をとってください。特定のライセンスの取得の義務化や推奨に関して影響する可能性があります。
- 資金提供者
- データリポジトリ
- 所属機関または学部
他人のデータを再利用する場合、元のライセンスの規約を確実に遵守するようにしてください。
ライセンスの選択肢
多くの場合、データはクリエイティブ・コモンズによるライセンスの下で共有されます。クリエイティブ・コモンズ(Creative Commons; CC)は、クリエイター自身の著作物を再利用できる条件についてパラメータを設定するために一連の選択肢を提供しています。
これらのライセンスは、あらゆる創作物に適用されます。特にデータにライセンスを付与する場合、データセットに保護しなければならない情報が含まれている場合を除き、広範な再利用を許可するライセンスを選ぶのが最良です。
CC0は、再利用について制約を設けないことからデータリポジトリの間で好まれています。また、クリエイティブ・コモンズは、以下のとおり、クリエイターがライセンスに含めることができる様々な制限も提供しています。
- 表示(CC BY) ― あなたのデータを使用する者は、あなたのクレジットを表示しなければなりません。もちろん、これはライセンスに関係なく学術的な再利用にも求められます。
- 改変禁止(CC ND) ― 他者があなたのデータセットをそのまま再利用することができますが、新しいデータセットを派生させるために組み替えたり一部を抽出することはできません。これは、再利用の可能性を大幅に制限します。
- 継承(CC SA) ― 他者があなたのデータセットから派生物を作ることができますが、元のデータセットに適用したものと同じCCライセンスの下で共有しなければなりません。
- 非営利(CC NC) ― あなたのデータはいかなる営利目的の下でも使用できません。
参考資料:
- データに適用するクリエイティブ・コモンズ・ライセンスの選び方に関するインフォグラフィックス (英語のみ)
- クリエイティブ・コモンズの各種ライセンスの全文 (言語切替機能あり)
- 一般的なソフトウェア・ライセンス (リンク切れ中)
エンバーゴ(公開制限期間)
データセットが完成しているもののまだ共有する準備ができていない場合は、エンバーゴ(公開制限期間)を設定できるリポジトリに投稿することを検討してください。
以下を含む数々の理由から、エンバーゴを設定した上で公開する方が、データの公開を待つよりも賢明です。
- 関連出版物へすぐに引用できる
- データファイルを保存する責任をリポジトリが持ってくれる
- あなたの出版物はエンバーゴの終了時に自動的に公開され、これについてあなたが手順を踏む必要はない
その間、データセットが確定し保護されているため、研究結果の発表に専念することができるのです。
例えば、九州大学学術情報リポジトリでも、データセットのエンバーゴを設定できます。
セキュリティ
多くの場合、データは関連するリスクレベルに応じたセキュリティ分類に従って整理されます。もしデータが世間に公開された場合、どのような結果になるかについて考えましょう。九州大学では、以下のグループにより構成される分類を設けています。
- 機密性3 ― 本学における業務で取り扱う情報のうち、九州大学法人文書管理規程(令和5年度九大規程第97号)第27条に定める秘密文書としての取扱いを要する情報
- 機密性2 ― 本学における業務で取り扱う情報のうち、独立行政法人等の保有する情報の公開に関する法律(平成13年12月5日法律第140号。以下「情報公開法」という。)第5条各号における不開示情報に該当すると判断される蓋然性の高い情報を含む情報であって、「機密性3情報」以外の情報
- 機密性1 ― 本学における業務で取り扱う情報のうち、情報公開法第5条各号におけ る不開示情報に該当すると判断される蓋然性の高い情報を含まない情報
機密データの変換
機密情報を含む保護すべきデータを共有するにはどうすればよいでしょうか?多くの場合、データを変換し、機密情報を完全に削除するか、機密情報でなくなるように変換する必要があります。
データをどのように変換するかは、以下の点によって決まります。
- データそのものの形式と内容
- 誰を保護するか、何を保護するかの脆弱性
- 誰がデータにアクセスできるか
これらの要件は、機密データをどのように変換するかについて一般的な感覚を示していますが、実際には変換方法は研究プロジェクトごとに異なります。実際のデータを扱う場合は、常にセキュリティの専門家に相談することをお勧めします。
データは可能な限りオープンであるべきですが、必要な限り制限されるべきであることも覚えておいてください。
考えられる識別子
名前、住所、ID番号といった明白な識別子がありますが、組み合わせることで個人を識別できるデータ項目は他にもたくさんあります。
米国保健福祉省は、The Safe Harbor method of de-identification(英語のみ)により、個人を特定できる可能性のあるデータをすべて削除することを推奨しています。
Data Nudgeニュースレターで公開したSafe Harbor methodの簡単な紹介もお読みください(リンク切れ)。
変換方法
機密情報を保護するためにデータを変換する方法は数多くあり、次のような方法もあります。
- 非識別化:識別子を削除するが、別の場所に保持することで、データと再接続できるようにする。
- 匿名化:識別子を完全に削除し、データと再び結びつけることができないようにする。
- 集約:特定の識別情報をより一般的な特徴に置き換える。
変換方法についてもっと詳しく知りたい方は、the Abdul Latif Jameel Poverty Action Labによるresearcher’s guide to de-identificationをお読みください。
日本におけるガイドライン:
個人情報の保護に関する法律についてのガイドライン(仮名加工情報・匿名加工情報編)
補足資料
たとえ将来の利用者があなただけであったとしても、書き留めておくようにしましょう。
共有とセキュリティのバランスは研究プロジェクトごとに異なりますが、どのようにバランスを図るとしても、今後の利用者のためにデータを適切に記録し文書にしておく必要があります。
何を記録すべきか
優れたデータに関する文書の重要なポイント:
- 誰がデータを収集したのか - 著者、共著者、貢献者
- いつ、どのように取得したのか - 出典を引用し、取得方法をメモしておくこと
- 主要用語はどのような意味なのか - 定義や測定単位を示すこと
- 何が含まれるのか - マニフェストファイル(ソフトウェアを動作させるために必要となる設定等)を保管しておくこと
- どのように扱ったのか - 変更点や使用したツールをメモしておくこと
- 他に知るべきことは何か - 関連する出版物を指し示しておくこと
テンプレート&例
データに関する文書についての参考資料(英語のみ):
保管
なぜ、どのように?
データを共有しなくても、データをどのように保管するかを考える必要があります。保管(preservation)はただ保存(save)するのとは違います。
ファイルの保存は受動的で、本を保存するようなものです。ただ本棚に入れて、そのままにしておけばよいのです。
保管はより能動的で、観葉植物を生かすように、もう少し注意を払う必要があります。目を離さず、場所を変えたり新しい鉢に移したりしなくてはなりません。
よく保管されたファイルとは、次のことができるファイルのことです。
- 見つける
- 開く
- 理解する
- 使う
データはどのくらいの間保管すべきか
データはどのくらい保管すべきでしょうか?答えは簡単ではありません。
簡単な答えは、資金提供者やその他の利害関係者が求める限りです。その後は、倫理性、有用性、そして費用を負担できる限りデータを保管すべきです。
保管については、以下の要素について考慮すべきです。
- 資金提供者の要件
- 研究分野にもたらす価値
- 出版社の要件
- 独自性
- 保管にかかる費用
- 複製にかかる費用
詳しくは、2021年1月に出版されたData Retention Considerations Data Nudgeをご覧ください。
日本では、大学がデータの保管期間を定めている場合があります。所属機関のルールに従いましょう。例えば、九州大学では「研究データの保存等に関するガイドライン」により、研究データ等の保存期間を10年と定めています。
データの最低保管期間に関する方針
一般的な最低保管期間の方針を紹介しましょう。
研究助成金を受けている場合、特定の要件について、公募要領や助成金の授与に関する文書を必ず確認するようにしてください。
最低保管期間が適用されない場合は、データを少なくとも5年間は保管するようにし、その後に改めて検討してください。
保管に関するヒント
将来、自身が利用するためだけの場合も含め、データの保管に次の項目が役に立つでしょう。
- 可能な限りリポジトリを使用すること(特にキュレーションサービスがあるもの)
- データと文書を一緒に保管し、定義や測定単位を示すこと
- 使用したソフトウェアとそのバージョンを記録しておくこと(後にファイルを開くためにこの情報が必要になるかもしれません)
- 使用したスクリプトを保存しておき、可能であればコードをデータとともに共有すること
- 使用したソフトウェアで簡単に再利用できるように、ネイティブフォーマット(元のソフトウェアのフォーマット)で1部保存しておくこと
- ソフトウェアが使えない場合に備え、オープンフォーマット(.csv、.txtなど)で1部保存しておくこと
どこに保管すべきか
データを保管するための最良の方法は、リポジトリを利用することです。リポジトリとは、データを保管し、見つけやすくアクセスしやすくするデジタルアーカイブのことです。多くのリポジトリは、デジタルオブジェクト識別子(DOI)とライセンス付与の選択肢を提供しており、データを共有することで著作者としてのクレジットが得られるようにしています。
ほとんどのリポジトリは、コレクション内のデータセットを広く公開していますが、中には機密性が高いデータへのアクセスを制限しているところもあります。また、公開日を遅らせるためにエンバーゴの設定が可能なリポジトリも数多くあります。
リポジトリの種類
第一候補 - ドメイン・リポジトリ
サブジェクトリポジトリ、分野別リポジトリとしても知られています。自身の研究分野に広く認知され信頼されているリポジトリが存在する場合、通常はそれが最良の選択肢です。
第二候補 - 機関リポジトリ
大学が運営するリポジトリは一般的に信頼性が非常に高く、特に学際的なデータについては有利です。
第三候補 - 汎用リポジトリ
誰もがデータを公開できるリポジトリは、上記リポジトリほどにはサポートを提供してくれませんが、ビッグデータのために、または機関リポジトリが使えない場合によい選択肢となることがあります。
例えば、九州大学の機関リポジトリである「九州大学学術情報リポジトリ(QIR)」では、研究データの公開を無料で行うことができます。データの提供者と相談しながら、公開方法の検討やメタデータ・DataCite DOIの付与などを行います。
リポジトリを見つける
Registry of Research Data Repositories(別名re3data)では、世界中のデータリポジトリの検索可能なインデックスを管理しています。一般的なGoogle検索では見落としてしまうようなリソースを見つけるには、その広範な検索機能とブラウズ機能を利用しましょう。
ファイル形式
古いファイルを開こうとしたら、もうそのソフトウェアにアクセスできなかったり、新しいソフトウェアがファイルの一部を壊してしまったりしたことはありませんか?データがどのようなファイル形式で保存されているかは、将来的にデータをどれだけ再利用できるかという点で、最も重要な要素の一つです。
保管に向いているファイル形式
完璧なファイル形式はなく、研究プロジェクトに合ったものを選択する際には通常何かを犠牲にする必要があります。選択肢を比較する際には、以下の要素を考慮してください。
| 保管に向いていない形式 | 保管に向いている形式 |
| 独自形式(MS Office) | オープン(Open Office、CSV) |
| 一般的でない形式(Open Office) | 一般的な形式(MS Office) |
| あまりサポートされていない形式(SPSS) | よくサボートされている形式(CSV、XML) |
| 埋め込まれている形式(マクロ付きExcel) | 埋め込まれていない形式(ASCII) |
| 圧縮(JPEG) | 非圧縮(TIFF、JPEG 2000) |
ファイル形式がどれだけ一般的かを判断する場合は、ご自身の研究分野にいる他の研究者および/またはデータの利用者のことを考えてください。
推奨する形式
The University of Illinois Conservation LabによるガイドDigital File Formats for Preservation: Decoded(英語のみ)では、以下のデータを保管するために推奨されるファイル形式を列挙しています。
- テキスト
- データセット
- 地理空間リソース
- 動画
- 静止画
- 音声
- ウェブリソース
可能であれば、多くのプログラムで開ける単純なファイル形式を選択してください。
- 表の場合 - .csv
- テキストの場合 - .txt
- 文書の場合 - .pdf
これらはLibrary of Congressによるfile format recommendations(英語のみ)に基づいています。
再利用
データを探す
データを見つける方法をいくつか紹介します。
- ある学術論文の根拠となっているデータを探したい場合は、当該論文の中で引用されているか、参照されているか、または補足資料として添付されているかどうかを確認してください。
- サブジェクトリポジトリまたはデータタイプに特化したリポジトリで検索してください。
- 作成者に連絡を取ってみてください。一部の研究者はデータをリポジトリに登録していなくても、リクエストがあれば共有してくれます。
- 図書館に相談してください。彼らは一般公開されているデータセットや、図書館を通じてアクセスできる専有データセットを見つけるのを助けてくれるでしょう。
データを検索できる場所
利用可能なデータセットを探し出すための出発点をいくつか紹介します。データセットが評判のよい情報源によるものであっても、その信頼性を評価する上ではご自身の常識に頼るようにしてください(英語のみ)。
Google Dataset Search - 特にデータについてオンライン上で幅広く検索するために良い出発点。
Re3data - 特定のタイプのデータリポジトリを探す場合は、re3dataで研究データリポジトリを確認してみましょう。
Data.gov - 米国政府は様々なテーマについてオープンデータセットを提供しています。
二次データを使う
次の項目は、データを再利用する上で来歴を維持するのに役立ちます。
- ライセンスを確認すること - どのような種類の再利用が許可されているのか?
- オリジナルコピーをロックすること - 作業用のコピーは別の場所に保存しましょう
- すべてのデータに関する文書に目を通し保存すること - オリジナルコピーとともに保管しましょう
- 自分のReadMeファイルを作ること - 変更や疑問を記録しましょう
- 著者に連絡を取ること - 思い込むのを避けましょう(または少なくともメモしましょう)
- 自身のバージョンを共有すること(ライセンスにより許可されている場合)
2021年8月のData Nudgeの10 Tips for Using and Managing Secondary Dataをご覧ください。
データを再利用すべきか?
エジンバラ大学が無償で提供しているオンラインのdata management courseによる2分間の動画(英語のみ)では、他人のデータを再利用することを検討している場合に確認すべき重要な質問について説明しています。
データを引用する
他の種類の資料を引用するのと同じように、データの引用も同等に重要なことです。データの引用がなければ、学術的な主張と、それを支持するデータを結び付けることが不可能になってしまいます。然るべき場所でクレジットを表示し、研究による主張の信頼性を評価し、データへのアクセスを改善するためにはデータの引用が必要なのです。
データ引用に関する参考文献(英語のみ):
- Data Curation Center(DCC) - データセットを引用し出版物へリンクする方法
- DOI Citation Formatter
- University of Illinois Data Nudge - データ引用について